综述 [] Unknown-material 给出了一个相当全面的视角, 明确地把 Agentic RL 和传统的 LLM RL 区分开来了. 传统 LLM RL 常常只是在固定 prompt 上优化一个回答, 而 Agentic RL 关心的是一个 LLM policy 在开放环境中如何观察/行动/调用工具/维护记忆/规划/修正策略, 并从长程反馈中学习.
综述给出的定义如下:
Agentic RL 指的是把 LLM 视作嵌入序列决策循环中的可学习策略, 并通过 RL 赋予它规划、推理、工具使用、记忆维护、自我反思等自主能力, 使其能在部分可观测、动态、长程环境中形成稳定行为.
从 LLM RL 到 Agentic RL
传统 RLHF 或 RFT 的基本图景一般是从人类偏好、奖励模型或可验证答案中得到奖励信号, 然后让语言模型更偏向高奖励输出.
偏好式 RFT 可以近似写成退化的马尔可夫决策过程 (MDP):
$$ \left\langle S_{\mathrm{trad}}, A_{\mathrm{trad}}, P_{\mathrm{trad}}, R_{\mathrm{trad}}, T=1,\gamma=1 \right\rangle $$而 Agentic RL 通常是这样的:
$$ \left\langle S_{\mathrm{agent}}, A_{\mathrm{agent}}, P_{\mathrm{agent}}, R_{\mathrm{agent}}, \gamma, O \right\rangle $$这里援引一下综述给出的对比表格:
| 概念 | 传统 LLM RL | Agentic RL |
|---|---|---|
| $S$ (状态空间) | $\{s_0\}$, 状态基本就是 prompt | $s_t \in \mathcal{S}_{\text{agent}}$, 拥有观察 $o_t = O(s_t)$, 通常 $T \gt 1$ |
| $A$ (动作空间) | 完整文本序列 | $A_{\text{agent}} = A_{\text{text}} \cup A_{\text{action}}$ 包含文本生成和环境交互动作 (如是否调用搜索引擎, 修改代码并运行测试) |
| $P$ (转移概率) | 直接转移到终止状态 | 动态转移函数 $P(s_{t+1} \mid s_t,a_t)$ |
| $R$ (奖励函数) | 往往只对完整回答打分 | 逐 step $R(s_t,a_t)$, 稀疏任务和紧密的子奖励 |
| $J(\theta)$ (优化目标) | $J(\theta) = \mathbb{E}_{a \sim \pi_0} [r(a)]$ | $J(\theta) = \mathbb{E}_{\tau \sim \pi_\theta} [\sum_{t=0}^T \gamma^t R(s_t,a_t)]$ |
算法Agentic-RL
输入 > 环境集合 $\mathcal{E}$, 初始 LLM policy $\pi_\theta$, 奖励函数或奖励模型 $R$, rollout budget $B$, 更新算法 $\mathcal{A}$.
输出 > 经过交互训练后的 agent policy $\pi_{\theta'}$.
- 从环境集合中采样任务 $e \sim \mathcal{E}$, 初始化状态 $s_0$ 和观察 $o_0$.
- 构造上下文 $h_0 = \mathrm{Prompt}(o_0, m_0, g)$, 其中 $m_0$ 是记忆, $g$ 是任务目标.
- 对 $t=0,\ldots,T-1$:
- 用 $\pi_\theta(a_t|h_t)$ 采样语义动作 $a_t$.
- 如果 $a_t$ 是工具调用, 则执行工具并写入观察; 如果是 GUI 或代码动作, 则更新外部环境.
- 环境返回 $o_{t+1}$, 奖励 $r_t$, 以及终止标记.
- 更新上下文 $h_{t+1}=\mathrm{Update}(h_t,a_t,o_{t+1},m_t)$.
- 收集轨迹 $\tau=(h_t,a_t,r_t)_{t=0}^{T}$.
- 用 $\mathcal{A}$ 更新策略, 例如 PPO、GRPO、DPO 或其他 actor-critic / preference optimization 变体.
- 重复步骤 1-5, 直到策略在验证环境中稳定提升.
重要文献坐标系
下面为 AI 辅助找出的重要文献
算法主线
Agentic RL 不是一个固定算法名, 它更像一个任务范式. 具体到优化层面, 综述把 PPO、DPO、GRPO 及其变体作为主干.
近端策略优化
近端策略优化 (Proximal Policy Optimization, PPO) [] 核心是限制新旧策略比率:
$$ \rho_t(\theta)=\frac{\pi_\theta(a_t|s_t)}{\pi_{\theta_{\mathrm{old}}}(a_t|s_t)} $$常用的 clipped objective:
$$ \mathcal{L}^{\mathrm{CLIP}}(\theta) = \mathbb{E}_t \left[ \min\left( \rho_t(\theta)\hat{A}_t, \mathrm{clip}(\rho_t(\theta),1-\epsilon,1+\epsilon)\hat{A}_t \right) \right] $$对 LLM 来说, PPO 的优点是清晰, 但它通常要 policy 和 value 两个模型, 还要处理长序列训练的显存和吞吐问题. 当 agent 进一步包含工具调用、环境状态和多轮交互时, PPO 的 rollout 与信用分配难度会进一步增加.
直接偏好优化
直接偏好优化 (Direct Preference Optimization, DPO) [] 绕开显式 reward 和在线 RL 循环, 直接从 pairwise preference 中优化 policy. 对于样本 $(x,y_w,y_l)$, DPO 形式上可写成:
$$ \mathcal{L}_{\mathrm{DPO}} = -\log \sigma \left( \beta \left[ \log\frac{\pi_\theta(y_w|x)}{\pi_{\mathrm{ref}}(y_w|x)} - \log\frac{\pi_\theta(y_l|x)}{\pi_{\mathrm{ref}}(y_l|x)} \right] \right) $$在 Agentic RL 中, DPO 不再比较两个短回答, 而是比较两个 action 片段.
组相对策略优化
DeepSeekMath [] 提出的组相对策略优化 (Group Relative Policy Optimization, GRPO) 可以看成 “去 critic 化” 的 PPO 变体. 它在同一 prompt 下采样一 “组” 输出, 即同一个问题采样多个解答, 可验证任务给每个解答打分, 组内比较就能得到相对优势. DeepSeek-R1 [] 进一步把这种思路推到了推理模型训练上.
算法GRPO
输入 > 任务 $x$, 当前策略 $\pi_\theta$, 参考策略 $\pi_{\mathrm{ref}}$, 每组采样数 $G$, 奖励函数 $R$.
输出 > 更新后的策略 $\pi_{\theta'}$.
- 对同一任务 $x$ 采样 $G$ 条 agent 轨迹: $\tau_1,\ldots,\tau_G$.
- 对每条轨迹执行环境评估, 得到 $r_i=R(x,\tau_i)$.
- 计算组内标准化优势: $$ \hat{A}_i=\frac{r_i-\mu_r}{\sigma_r+\epsilon} $$
- 对每条轨迹中的 token / action 计算新旧策略比率.
- 使用 clipped policy objective 计算损失: $$ \mathcal{L}^{\mathrm{GRPO}}(\theta) = \frac{1}{G}\sum_{i=1}^G \min\left( \rho_i(\theta)\hat{A}_i, \mathrm{clip}(\rho_i(\theta),1-\epsilon,1+\epsilon)\hat{A}_i \right) $$
- 加入 KL 散度正则, 避免策略偏离 $\pi_{\mathrm{ref}}$ 过远.
- 重复采样和更新.
能力视角
综述的第三节按能力拆解 Agentic RL.
计划
早期 agent planning 常靠提示词工程. ReAct [] Unknown-material (ICLR 2023 Notable) 的关键贡献在于把推理轨迹和动作交错在一起. 论文的关键建模方式是把原本的动作空间 $A$ 扩展成 $\hat{A} = A \cup L$, 其中 $L$ 是语言空间.
算法ReAct
输入 > 任务输入 $x$, 外部环境/工具 $\mathcal{E}$, LLM policy $\pi_\theta$, 动作空间 $\mathcal{A}$, 语言推理空间 $\mathcal{L}$, 最大交互步数 $T$, few-shot ReAct 示例 $\mathcal{D}_{demo}$.
输出 > 最终答案/任务结果 $y$, 以及推理-行动轨迹 $\tau$.
-
初始化上下文
$$ h_0 = [\mathcal{D}_{demo}; x], $$初始化轨迹 $\tau=\emptyset$.
-
对 $t=0,1,\dots,T-1$, 模型基于当前上下文生成下一步:
$$ z_t \sim \pi_\theta(\cdot \mid h_t) $$ -
如果是自然语言推理 $z_t=\texttt{Thought}(r_t)$, 将推理文本加入轨迹, 并更新上下文:
$$ \tau \leftarrow \tau \cup { \texttt{Thought}(r_t) } $$
$$ h_{t+1} = h_t \oplus \texttt{Thought}(r_t) $$ -
如果是对环境执行的动作 $z_t=\texttt{Action}(a_t)$, 在环境中执行动作, 并将动作和观察写入轨迹:
$$ o_t = \mathcal{E}(a_t) $$
$$ \tau \leftarrow \tau \cup { \texttt{Action}(a_t), \texttt{Observation}(o_t) } $$
$$ h_{t+1} = h_t \oplus \texttt{Action}(a_t) \oplus \texttt{Observation}(o_t) $$ -
如果是最终答案或任务完成信号, $z_t=\texttt{Finish}(y)$, 将最终答案写入轨迹:
$$ \tau \leftarrow \tau \cup { \texttt{Finish}(y) } $$随后结束 rollout, 返回 $(y,\tau)$.
Tree of Thoughts [] (NIPS 2023 Oral) 则把思考链扩展成了思考树, 它把思考当作可扩展节点, 让模型生成、评估和回溯.
对于思考生成, 从当前状态 $s=[x,z_{1:i}]$ 生成 $k$ 个候选思考, 论文给了两种方式 (对应算法的 $G$):
- 一种是从 CoT prompt 独立采样多个候选, 适合开放空间
- 另一种是一个 prompt 里连续生成 k 个不同的下一步, 适合约束较强的任务.
对于状态评估, 这个是 ToT 框架最大的创新之一, 就是利用 LLM 自己来充当评估器, 为搜索算法提供启发式信息, 也有两种方式 (对应算法的 $V$):
- 价值评估: 让 LLM 直接给当前状态打分, 或者给出一个分类 (比如 sure/likely/impossible)
- 投票表决: 让 LLM 比较几个不同的分支, 然后投票选出最有希望的一个.

关于模型推理, 论文给出了 BFS 和 DFS 两种流程, 这里以 DFS 为例:
算法Tree of Thought - DFS
输入 > 当前状态 $s$, 当前深度 $t$, LLM policy $p_\theta$, 思考生成器 $G$, 每个状态生成候选数 $k$, state evaluator $V$, 最大深度 $T$, 剪枝阈值 $v_{\mathrm{th}}$.
输出 > 候选答案集合 $\mathcal{Y}$, 搜索轨迹 $\tau$.
-
如果 $t>T$, 基于当前状态生成最终答案并返回.
$$ y = G(p_\theta, s, 1) $$
$$ \mathcal{Y} \leftarrow \mathcal{Y} \cup {y} $$ -
从当前状态生成 $k$ 个候选下一步 thought:
$$ Z = G(p_\theta, s, k) $$ -
对每个候选 thought $z \in Z$, 构造新状态:
$$ s'=[s,z] $$ -
对新状态进行评估:
$$ v = V(p_\theta,{s'})(s') $$ -
如果 $v > v_{\mathrm{th}}$, 递归搜索:
$$ \texttt{DFS}(s',t+1) $$ -
返回候选答案集合 $\mathcal{Y}$ 和完整搜索轨迹 $\tau$.
RAP [] 更进一步, 把 LLM 复用成世界模型和推理 agent, 用 MCTS 探索推理树, 这里不再赘述.
这几篇文献的共同点是, planning 不只是生成计划, 而是搜索计划空间. 接入 RL 后, 它可以训练价值函数, 训练计划选择, 甚至直接训练策略产生更好的计划动作.
工具调用
工具调用可以被看成一种离散行动:
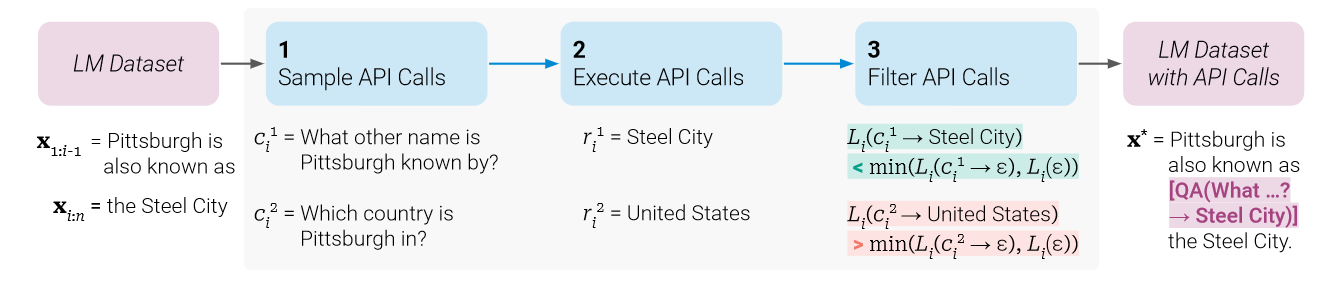
$$ a_t=(\mathrm{tool\_name}, \mathrm{arguments}) $$Toolformer [] Unknown-material (NIPS 2023 Oral) 证明语言模型可以通过自监督方式学会 API 调用: 模型先生成候选 API 调用, 执行工具, 再过滤出能提升语言模型似然的调用样本.
算法Toolformer-API-Annotation
输入 > 普通文本语料 $\mathcal{C}={x^{(1)},\dots,x^{(N)}}$, 基础语言模型 $M$, API 集合 $\mathcal{A}$, 每个 API 的少量 demonstration prompt $P_a(\cdot)$, 最大候选位置数 $k$, 每个位置最大候选 API call 数 $m$, 采样阈值 $\tau_s$, 过滤阈值 $\tau_f$.
输出 > 带 API 调用标注的语料 $\mathcal{C}^{*}$.
-
初始化 $\mathcal{C}^{*}\leftarrow \emptyset$.
-
对每篇文本 $x=(x_1,\dots,x_n)\in \mathcal{C}$ 和每个工具/API $a\in \mathcal{A}$ 构造 few-shot API 标注的 prompt $P_a(x)$, 比如形如
<API>a(i)</API>, 展示如何在普通文本中插入该 API 的调用格式. -
对每个 token 位置 $i$, 计算模型在该位置开始 API 调用的概率:
$$ p_i = p_M(\langle API\rangle \mid P_a(x), x_{1:i-1}) $$ -
保留满足阈值的位置:
$$ I=\{i \mid p_i>\tau_s \} $$如果 $|I|>k$, 只保留概率最高的 $k$ 个位置.
-
对每个候选位置 $i\in I$, 从模型中采样最多 $m$ 个 API 调用并执行:
$$ c_i^1,\dots,c_i^m \sim M(P_a(x),x_{1:i-1},\langle API\rangle) $$
$$ r_i^j = a(c_i^j) $$ -
对每个候选调用 $(c_i^j,r_i^j)$, 计算不调用工具/只给 API 输入, 不给工具返回/给 API 输入和工具返回三种情况下模型预测未来 token 的 loss:
$$ L_i(\epsilon), ~ L_i(e(c_i^j,\epsilon)), ~ L_i(e(c_i^j,r_i^j)) $$ -
定义:
$$ L_i^+ = L_i(e(c_i^j,r_i^j)) $$$$ L_i^- = \min \left(L_i(\epsilon), L_i(e(c_i^j,\epsilon))\right) $$如果工具返回真的帮助模型预测后续文本, 即:
$$ L_i^- - L_i^+ \geq \tau_f $$则保留该 API call.
-
将所有保留的 API call 插入原始文本:
$$ x^* = x_{1:i-1}, e(c_i,r_i), x_{i:n} $$
$$ \mathcal{C}^{*}\leftarrow \mathcal{C}^{*}\cup {x^*} $$ -
返回 $\mathcal{C}^{*}$.
Search-R1 [] Unknown-material 是一个很典型的 Agentic RL 方向, 让模型在逐步推理中通过 RL 学会多轮搜索查询, 并处理实时检索结果.
算法Search-R1
输入 > 问题 $q$, 搜索工具 $\mathcal{S}$, LLM policy $\pi_\theta$, 最大搜索次数 $K$.
输出 > 答案 $y$ 和搜索-推理轨迹 $\tau$.
- 初始化上下文 $h_0=q$, 搜索次数 $k=0$.
- 模型生成下一步: 推理文本、搜索请求或最终答案.
- 如果动作为
Search(query)且 $k\lt K$ :- 执行 $\mathcal{S}(\mathrm{query})$.
- 把检索结果作为 observation 写入上下文.
- $k \leftarrow k+1$.
- 如果动作为
Answer(y), 结束 rollout. - 用最终答案正确性、搜索成本、格式合法性等构造 reward.
- 通过 GRPO / PPO 更新 policy.
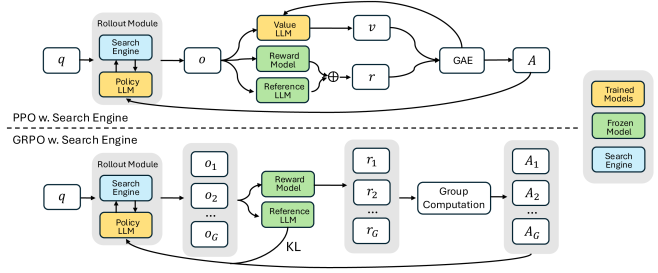
其奖励设计非常简单——精准匹配0/1奖励. 此外实测发现 GRPO 收敛快, 但训练后期容易奖励崩塌, PPO 虽然收敛慢, 但更稳定, 最终性能更好, 所以默认用 PPO.
记忆
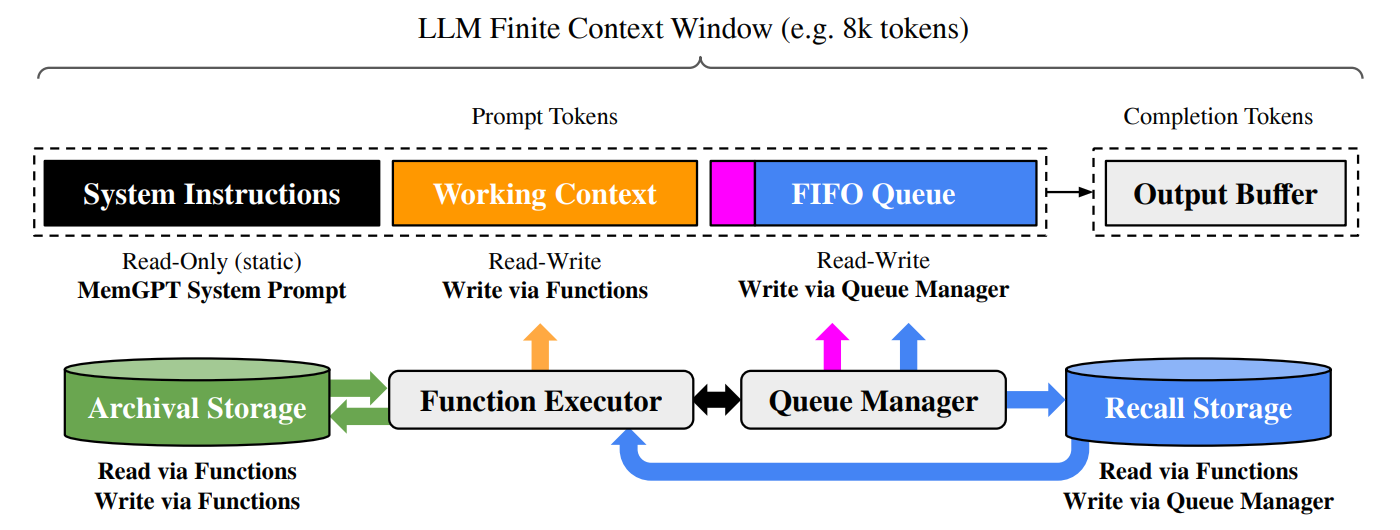
MemGPT [] Unknown-material 借鉴传统操作系统中虚拟内存管理的核心思想, 提出一种分层记忆系统, 使其能够智能地在快速但有限的"主上下文" (类比 RAM) 和慢速但海量的"外部上下文" (类比磁盘) 之间进行信息的换入换出.
运作机制:
- 用户输入、系统警告 (如主上下文接近上限, 产生内存压力) 或其他预设会触发 LLM 进行推理.
- LLM根据系统指令和当前上下文, 决定是否需要以及如何管理其记忆. 例如: 当FIFO队列过长, 触发“内存压力”警告, LLM可以调用函数将队列中的重要信息存入工作上下文或档案存储.
- 当需要回忆过去的对话细节或查询文档时, LLM调用函数从回忆存储或档案存储中检索信息, 并将其加载到主上下文中. 当工作上下文中的信息过时或不再相关, LLM可以更新或移除它们.
- 函数执行的结果 (包括成功信息或错误信息) 会反馈给LLM, 更新其主上下文, 并可能触发后续的函数调用链 (例如分页查询) .

这里所有调用函数都是由 LLM 自己决定的, 包括何时调用、调用哪个函数、以及如何处理函数返回的结果. 这种设计使得 LLM 不仅是一个被动的记忆存储器, 而是一个主动的记忆管理者, 能够根据当前任务需求和系统状态动态调整其记忆策略.
Reflexion [] (NIPS 2023) 不更新模型权重, 而是让 agent 根据失败反馈写下文字反馈, 存入片段性的记忆, 供下一次尝试使用. 把语言形式的经验当作一种近似的策略提升.
推理
DeepSeek-R1 [] 指出大规模 RL 可以在没有人工标注推理轨迹的情况下诱导出某些推理行为. 不过, 综述中特别提到过度思考的现象: agentic 推理可能因为过度搜索、过度验证、工具调用循环而变慢甚至变差.
任务视角
综述第四节按任务展开. AI 辅助整理如下:
| 任务 | 环境真实性 | 奖励可验证性 | 难点 |
|---|---|---|---|
| 数学推理 | 低 | 高 | reward 容易, 但容易过拟合格式和长度 |
| 代码生成 | 中 | 高 | 单函数任务较清晰, 仓库级任务信用分配难 |
| 搜索研究 | 中 | 中 | 信息质量、引用可靠性和搜索成本难统一 |
| Web / GUI | 高 | 中 | 观测/动作接地难 |
| 软件工程 | 高 | 高 | 测试、构建、依赖和长上下文开销大 |
| 具身 | 高 | 低 | 稀疏奖励、长 horizon、环境随机性 |
| 多智能体 | 高 | 低 | 非平稳性、协作信用分配、通信协议 |
Search Agent
网页搜索是最自然的 agentic 任务之一. 简单 RAG 通常把检索当成固定预处理, 但 research agent 需要决定搜索计划、重写查询、交叉验证来源、归纳冲突信息、生成报告.
Search-R1 [] 让模型通过 RL 学会在推理过程中主动搜索. 它比较接近 ReAct, 但重点从 prompt 模式变成了策略训练. 这类任务的 reward 设计通常要考虑多方面因素:
$$ R = R_{\mathrm{answer}} + \lambda_1 R_{\mathrm{citation}} - \lambda_2 C_{\mathrm{search}} - \lambda_3 R_{\mathrm{hallucination}} $$其中 $C_{\mathrm{search}}$ 是搜索成本, $R_{\mathrm{citation}}$ 是来源支撑度, $R_{\mathrm{hallucination}}$ 则惩罚无来源断言.
Code / SWE Agent
SWE-bench [] (ICLR 2024) 给出了一种仓库级 benchmark. 它从 12 个流行 Python 仓库抓取约 9 万个 PR;再保留 merged、关联 issue、且修改测试文件的 PR;最后用执行过滤验证这些 PR 是否能产生 fail-to-pass 测试. 一个 SWE-bench task instance 可以抽象成:
$$ \mathcal{I} = (P, C, T, \delta) $$其中:
- $P$: problem statement, 也就是 GitHub issue 文本;
- $C$: 代码库在 PR base commit 处的快照;
- $T$: 由 PR 中测试文件变化提取出的测试集合;
- $\delta$: 真实 PR 的 gold patch, 也是模型要预测的目标.
需要注意, 模型可以生成和真实 PR 不一样的 patch, 只要能解决 issue 并保持已有测试通过, 就算成功
Math Agent
数学任务是 RLVR 最合适的温床. 主要在于其答案通常可验证, 采样多个解答再组内比较也容易. DeepSeekMath 和 DeepSeek-R1 的路径说明, 在数学和形式化任务上, GRPO / PPO 这类方法能诱导更长、更自检的推理过程.
形式数学里的 reward 更可验证, 但动作空间也更困难. 而非形式数学则较难以检查过程正确性.
GUI / Web Agent
综述 [] 有关 GUI Agent 只列举了几个 Benchmark: WebShop [] 是早期网络环境, agent 根据商品需求导航网页、搜索、筛选并购买. WebArena [] 则把 web agent 推向更真实的自发主持的网站环境, 包括电商、论坛、代码协作和内容管理等网站. OSWorld [] 的 benchmark 进一步让 agent 操作真实桌面系统和应用.
由于此课题目前我们更关注, 我又检索到有关 GUI Agent 的另一篇综述 [] .
小结
这篇综述 [] 相当详细, 分成了如上所说的几个方面. 其中任何一项缺失, 都很难称为真正的 Agentic RL.
从我理解来看, 和一般的 RL 相比, agentic RL 具有明显的自发性——它不像传统 RL 那样在一个固定环境里被动学习, 并接受一个人为设计的奖励函数, 而是需要在一个开放动态的环境中, 自主地观察行动和修正策略, 在此期间模型还可以借助各种工具, 来填补记忆存储的空白. “Planning” 这个概念也相当独特, 这意味着模型需要能够在面对复杂问题时自发拆解, 规划行动路径. 它显然并不是用于完成某一项固定的任务, 而是需要通过广泛的动作空间和环境观察, 提升自身对不同环境的泛化适应能力.
参考文献
- Zhang, G., Geng, H., Yu, X., Yin, Z., Zhang, Z., Tan, Z., Zhou, H., Li, Z., Xue, X., Li, Y., Zhou, Y., Chen, Y., Zhang, C., Fan, Y., Wang, Z., Huang, S., Liao, Y., Wang, H., Yang, M., Ji, H., Wang, J., Yan, S., Torr, P., and Bai, L. The Landscape of Agentic Reinforcement Learning for LLMs: A Survey. Transactions on Machine Learning Research, 2026.
- Christiano, P. F., Leike, J., Brown, T., Martic, M., Legg, S., and Amodei, D. Deep reinforcement learning from human preferences. Advances in Neural Information Processing Systems, 2017.
- Ouyang, L., Wu, J., Jiang, X., et al. Training language models to follow instructions with human feedback. Advances in Neural Information Processing Systems, 2022.
- Schulman, J., Wolski, F., Dhariwal, P., Radford, A., and Klimov, O. Proximal policy optimization algorithms. arXiv:1707.06347, 2017.
- Rafailov, R., Sharma, A., Mitchell, E., Ermon, S., Manning, C. D., and Finn, C. Direct Preference Optimization: Your Language Model is Secretly a Reward Model. Advances in Neural Information Processing Systems, 2023.
- Shao, Z., Wang, P., Zhu, Q., et al. DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models. arXiv:2402.03300, 2024.
- DeepSeek-AI. DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning. arXiv:2501.12948, 2025.
- Yao, S., Zhao, J., Yu, D., et al. ReAct: Synergizing Reasoning and Acting in Language Models. International Conference on Learning Representations, 2023.
- Yao, S., Yu, D., Zhao, J., et al. Tree of Thoughts: Deliberate Problem Solving with Large Language Models. Advances in Neural Information Processing Systems, 2023.
- Hao, S., Gu, Y., Ma, H., Hong, J. J., Wang, Z., Wang, D. Z., and Hu, Z. Reasoning with Language Model is Planning with World Model. Empirical Methods in Natural Language Processing, 2023.
- Zhou, A., Yan, K., Shlapentokh-Rothman, M., Wang, H., and Wang, Y.-X. Language Agent Tree Search Unifies Reasoning Acting and Planning in Language Models. International Conference on Machine Learning, 2024.
- Schick, T., Dwivedi-Yu, J., Dessi, R., et al. Toolformer: Language Models Can Teach Themselves to Use Tools. Advances in Neural Information Processing Systems, 2023.
- Shinn, N., Cassano, F., Berman, E., Gopinath, A., Narasimhan, K., and Yao, S. Reflexion: Language Agents with Verbal Reinforcement Learning. Advances in Neural Information Processing Systems, 2023.
- Packer, C., Wooders, S., Lin, K., Fang, V., Patil, S. G., Stoica, I., and Gonzalez, J. E. MemGPT: Towards LLMs as Operating Systems. arXiv:2310.08560, 2023.
- Lightman, H., Kosaraju, V., Burda, Y., et al. Let's Verify Step by Step. arXiv:2305.20050, 2023.
- Yao, S., Chen, H., Yang, J., and Narasimhan, K. WebShop: Towards Scalable Real-World Web Interaction with Grounded Language Agents. Advances in Neural Information Processing Systems, 2022.
- Zhou, S., Xu, F. F., Zhu, H., et al. WebArena: A Realistic Web Environment for Building Autonomous Agents. International Conference on Learning Representations, 2024.
- Xie, T., Zhang, D., Chen, J., et al. OSWorld: Benchmarking Multimodal Agents for Open-Ended Tasks in Real Computer Environments. Advances in Neural Information Processing Systems, 2024.
- Jimenez, C. E., Yang, J., Wettig, A., Yao, S., Pei, K., Press, O., and Narasimhan, K. SWE-bench: Can Language Models Resolve Real-World GitHub Issues? International Conference on Learning Representations, 2024.
- Liu, X., Yu, H., Zhang, H., et al. AgentBench: Evaluating LLMs as Agents. International Conference on Learning Representations, 2024.
- Xi, Z., Ding, Y., Chen, W., et al. AgentGym: Evaluating and Training Large Language Model-based Agents across Diverse Environments. Annual Meeting of the Association for Computational Linguistics, 2025.
- Jin, B., Zeng, H., Yue, Z., Wang, D., Zamani, H., and Han, J. Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning. arXiv:2503.09516, 2025.
- Hu, J., Wu, X., Zhu, Z., Xianyu, Wang, W., Zhang, D., and Cao, Y. OpenRLHF: An Easy-to-use, Scalable and High-performance RLHF Framework. arXiv:2405.11143, 2024.
- von Werra, L., Belkada, Y., Tunstall, L., et al. TRL: Transformer Reinforcement Learning. Hugging Face, 2020.
- Luo, X., Zhang, Y., He, Z., Wang, Z., Zhao, S., Li, D., Qiu, L. K., and Yang, Y. Agent Lightning: Train ANY AI Agents with Reinforcement Learning. arXiv:2508.03680, 2025.
- Wang, G., Xie, Y., Jiang, Y., et al. Voyager: An Open-Ended Embodied Agent with Large Language Models. Transactions on Machine Learning Research, 2024.