在 智能体强化学习总览 和 GUI 智能体 里, 我们已经反复看到一个现象: 现在的多模态智能体 (Multimodal Agent) 不缺工具, 缺的是稳定地选择、组合和复用工具的能力.
XSkill

论文 [] Unknown-material 不更新模型参数, 而是从历史多模态工具调用轨迹中提炼两类外部知识:
- 经验 (Experience): 面向局部决策的条件-动作建议
- 技能 (Skill): 面向任务流程的结构化工作流和工具模板
论文把当前多模态智能体的问题概括为两点:
- 工具使用低效. 模型可能对简单问题过度调用工具, 对复杂问题又探索不够深.
- 工具编排僵硬. 很多系统偏向单路径执行, 缺少跨任务迁移的工具组合模式.
XSkill 认为这两个问题需要两种粒度不同的知识来解决. 技能负责高层结构, 经验负责局部策略.
知识表示
论文把技能库和经验库分开维护:
$$ KB=(K,E) $$其中 $K$ 是 Markdown 形式的 Skill Library, $E$ 是 JSON 形式的 Experience Bank.
技能定义为:
$$ k=(M,W,P) \in K $$$M$ 是元信息, 包括技能名称、描述和版本; $W$ 是工作流序列; $P$ 是可复用工具模板. 比如一个视觉识别技能里, $W$ 可能包含“检查朝向、裁剪目标、增强图像、搜索图片来源”的流程, $P$ 则包含 Python 图像旋转、裁剪、放大的代码模板.
经验定义为:
$$ e=(c,a,v_e) \in E $$$c$ 是触发条件, $a$ 是建议动作, $v_e$ 是用于检索的语义向量. 论文限制单条经验的文本长度, 使它更像短的策略性 prompt, 而非完整轨迹复述.
问题建模
论文把多模态工具调用任务建模成 POMDP. 一个任务为:
$$ T=(q,I) $$其中 $q$ 是自然语言问题, $I=\{I_1,I_2,\ldots,I_m\}$ 是相关图像集合. 工具集合为:
$$ F=\{f_1,f_2,\ldots,f_n\} $$包括代码执行、网页搜索、图片搜索、网页访问等. 每一步 agent 根据当前状态和观察选择工具动作, 形成轨迹:
$$ \tau=[(s_0,a_0,o_0),\ldots,(s_T,a_T,o_T)] $$最终构造外部知识库:
$$ \max_{KB} P[\hat{y}=y^\ast \mid T, KB] $$整体框架
XSkill 分成两个阶段: 积累 (Accumulation) 和求解 (Inference). 论文中还区分了两个模型角色:
- $\mathrm{MLLM}_{exec}$: 负责实际执行工具调用和回答问题.
- $\mathrm{MLLM}_{kb}$: 负责总结轨迹、抽取经验、合并技能、重写检索结果.
算法XSkill: 双流知识循环
输入 > 训练任务集合 $\mathcal{D}_{train}$, 测试任务 $T=(q,I)$, 工具集合 $F$, 执行模型 $\mathrm{MLLM}_{exec}$, 知识管理模型 $\mathrm{MLLM}_{kb}$, 技能库 $K$, 经验库 $E$.
输出 > 最终答案 $\hat{y}$, 更新后的知识库 $KB=(K,E)$.
- 对训练任务 $T_i=(q_i,I_i)$ 执行 $N$ 条独立 rollout: $$ R_i=\{\tau_i^{(1)},\ldots,\tau_i^{(N)}\} $$
- 用 $\mathrm{MLLM}_{kb}$ 对轨迹、图像、问题和标准答案做视觉锚定总结: $$ S_{R_i},\Delta K_i=\mathrm{MLLM}_{kb}(R_i,I_i,q_i,y_i^\ast,K_{adapted}) $$ 其中 $S_{R_i}$ 记录关键决策点、工具模式和失败原因, $\Delta K_i$ 是从成功轨迹中抽出的技能片段.
- 做跨 rollout 批判 (Cross-Rollout Critique), 对成功和失败轨迹进行对比: $$ \Delta E_i=\mathrm{MLLM}_{kb}(S_{R_i},y_i^\ast,E_{ret}) $$
- 将 $\Delta E_i$ 中的经验加入 Experience Bank, 对相似经验按向量相似度合并, 并删除低质量或过度具体的条目.
- 将 $\Delta K_i$ 合并到 Skill Library, 对冗长技能做压缩、去重和变量化.
- 对测试任务 $T=(q,I)$, 先把问题分解成若干抽象子任务: $$ G=\{g_1,\ldots,g_{n_g}\} $$
- 对每个子任务检索相关经验: $$ E_{ret}=\bigcup_{g\in G}\mathrm{Top}\text{-}k(\{e\in E\mid \cos(v_g,v_e)>\tau_{min}\}) $$
- 结合当前图像和问题重写经验: $$ E_{rewritten}=\mathrm{MLLM}_{kb}(E_{ret},q,I) $$
- 结合重写后的经验, 对全局技能文档做任务适配: $$ K_{adapted}=\mathrm{MLLM}_{kb}(K,E_{rewritten},q,I) $$
- 将 $K_{adapted}$ 和 $E_{rewritten}$ 作为非强制参考注入 system prompt, 由 $\mathrm{MLLM}_{exec}$ 执行工具调用并输出答案.
- 记录实际使用了哪些技能和经验, 将使用历史回流到下一轮积累.
可以看到, XSkill 在总结、检索和改写时都显式把图像观察放进去了.

积累阶段
rollout summary. $\mathrm{MLLM}_{exec}$ 对同一个训练任务执行 $N$ 次, 得到成功和失败轨迹. $\mathrm{MLLM}_{kb}$ 看到的是完整多模态上下文: 图像、工具调用、中间输出、最终答案和 ground truth.
然后是 cross-rollout critique. 这一步对比成功和失败轨迹, 抽取导致结果差异的因素, 输出对经验库的结构化操作:
$$ \Delta E_i=\{op_1,op_2,\ldots,op_M\} $$每个操作是 add 或 modify. 如果新经验和已有经验相似度超过阈值, 系统会让 $\mathrm{MLLM}_{kb}$ 合并这些条目.
技能库的合并也类似. 从 rollout 中抽出的 workflow 和 tool template 会被合并进全局 Markdown 技能文档. 当技能文档超过长度阈值时, 系统会删除过度具体的细节. 这一步把 agent 轨迹整理成一份会不断演化的 SKILL.md.
推理阶段
推理阶段有三个设计点: 任务分解、上下文改写、非强制注入.
直接用原始问题去检索经验通常不够好, 所以 XSkill 先让 $\mathrm{MLLM}_{kb}$ 根据问题和图像分解出多个技术子任务, 再分别检索经验. 检索到的经验也不会直接塞进 prompt. 系统会先做 experience rewrite, 把通用经验改写成当前任务相关的建议.
随后系统会做 skill adaptation, 从全局技能库中剪掉无关章节, 把相关经验融进工作流, 并调整代码模板. 论文强调注入方式是非强制的参考.
ReSeek
论文 [] Unknown-material 讨论的是搜索智能体的自我纠错问题. ReSeek 直接把判断检索信息是否有用变成 agent 的一个内部动作, 并用强化学习训练这个动作.
现有搜索 agent 常见的问题是: 一旦第一次 search query 走错, 后续推理会沿着错误证据继续滚下去. ReSeek 的核心改动是加入一个特殊动作 JUDGE.
JUDGE 动作
ReSeek 把搜索过程建模为 MDP. 策略 $\pi_\theta$ 在每一步根据状态 $s_t$ 生成动作 $a_t$. 动作空间不仅包括搜索和回答, 还包括判断. 论文的训练方法使用 GRPO.
当 agent 得到一次搜索结果 $o_t$ 后, 它生成判断 $j_t\in\{\mathrm{Yes},\mathrm{No}\}$. 这个 judgment 不会物理删除历史, 而是作为 soft removal 信号写回上下文:
$$ C_t=\tau_{t-1}\oplus a_t\oplus o_t\oplus j_t $$如果 $j_t=\mathrm{Yes}$, 后续策略应该继续利用这条证据; 如果 $j_t=\mathrm{No}$, 后续策略应该语义上忽略这条路径, 重新搜索.
奖励函数
ReSeek 的奖励由两部分组成. 终止时使用答案正确性奖励, 即精准匹配预测答案和标准答案.
关键问题是怎么知道一次检索结果到底有没有用。论文用 bge-reranker-large 计算观察 $o_t$ 和真实答案 $gt$ 的相关性:
然后用 agent 生成的 $j_t$ 和理想判断 $j_t^\ast$ 比较:
$$ R_{\mathrm{judge}}(j_t,j_t^\ast)= \begin{cases} R_{\mathrm{match}}, & j_t=j_t^\ast \\ R_{\mathrm{mismatch}}, & j_t\ne j_t^\ast \end{cases} $$论文里匹配奖励是 $+0.3$. 惩罚是不对称的: 错把无用信息判断为有用, 惩罚 $-0.6$; 错把有用信息丢掉, 惩罚 $-0.3$.
结构化 Prompt
ReSeek 的 prompt 强制规定每次 search 后必须 judge:
- 新信息进入后先在
<think>中推理. - 需要外部知识时调用
<search> query </search>. - 收到搜索结果后, 必须输出
<judge>Yes</judge>或<judge>No</judge>. - 如果信息有用但还不够, 必须继续搜索.
- 如果信息无用, 必须继续搜索, 不能直接回答.
- 只有信息足够时才输出
<answer>...</answer>.
算法ReSeek: 搜索自纠错
输入 > 问题 $q$, 搜索环境 $\mathcal{E}$, 策略 $\pi_\theta$, 最大工具步数 $T$, reranker 阈值 $\tau=0.7$.
输出 > 答案 $\hat{a}$, 搜索轨迹 $\mathcal{T}$.
- 初始化上下文 $C_0=q$.
- 对 $t=1,\ldots,T$: $$ a_t\sim\pi_\theta(\cdot|C_{t-1}) $$
- 如果 $a_t$ 是搜索 $\texttt{query}$, 搜索环境返回观察: $$ o_t=\mathcal{E}(query) $$
- agent 对 $o_t$ 执行判断: $$ j_t\in\{\mathrm{Yes},\mathrm{No}\} $$
- 训练时, 用 reranker 和标准答案构造理想判断: $$ j_t^\ast=\mathbf{1}\{\mathrm{score}(o_t,gt)>0.7\} $$
- 根据 $j_t$ 和 $j_t^\ast$ 给出 $R_{\mathrm{judge}}$.
- 更新上下文: $$ C_t=C_{t-1}\oplus a_t\oplus o_t\oplus j_t $$
- 如果 $j_t=\mathrm{No}$, 下一步必须继续搜索; 如果 $j_t=\mathrm{Yes}$ 且信息不足, 下一步继续搜索; 如果信息足够, 输出
<answer>. - 终止时根据 Exact Match 给出 $R_{\mathrm{answer}}$.

FictionalHot
论文还提出了一个新的 Benchmark FictionalHot. 动机是搜索类 QA benchmark 很容易被预训练数据污染, 模型可能不是通过搜索推理答对, 而是早就记住了答案.
FictionalHot 的构造方法是:
- 从 NQ、TriviaQA、PopQA、HotpotQA、2Wiki、Musique 等数据集中抽样.
- 用 GPT-5 改写问题, 把真实实体替换成虚构实体, 但保留原有推理结构.
- 同时生成新的 Wikipedia 风格文档, 给这些虚构实体赋予世界事实.
- 把合成样本插入 2018 Wikipedia corpus, 作为新的检索语料.

实验
多跳任务上的提升更明显.
- 7B 模型在 Bamboogle 上, Search-R1 是 0.368, ZeroSearch 是 0.278, ReSeek 是 0.392;
- 在 FictionalHot 上, 7B 的直接推理只有 0.001, ReSeek 是 0.061;
- 3B 的直接推理也是 0.001, ReSeek 是 0.059.
这说明 FictionalHot 确实削弱了参数记忆优势, 更考验检索和过程推理.
OS-Symphony
论文 [] Unknown-material (ACL 2026, Zichen Ding) 讨论的是 CUA 框架, 针对的是 GUI agent 在执行未见长程任务时的鲁棒性问题. 它把当前 GUI agent 容易失败的地方拆成几个可协作模块: 一个负责决策的 Orchestrator, 一个负责运行时审计和长期记忆的 Reflection-Memory Agent (RMA), 以及 Searcher / Grounder / Coder 等工具 agent.
整体框架
OS-Symphony 的核心是 Orchestrator. 它在每一步输出 thought 和 action:
$$ t_i,a_i=F_O(I,R_i,o_i,T,H_{\mathrm{short}}) $$其中 $I$ 是用户指令, $R_i$ 是 RMA feedback, $o_i$ 是当前截图, $T$ 是 Searcher 返回的教程, $H_{\mathrm{short}}$ 是最近 $K$ 步的滑动窗口:
$$ H_{\mathrm{short}}=\{(o_j,t_j,a_j)\}_{j=i-K+1}^{i-1} $$也就是说 Orchestrator 只看最近几步和 RMA 提炼后的关键信息. 完整历史的压缩和纠错责任交给 RMA.
算法OS-Symphony
输入 > 任务指令 $I$, GUI 环境 $\mathcal{E}$, Orchestrator $F_O$, RMA $F_R$, 步骤总结器 $F_S$, 工具集合 $\mathcal{T}$.
输出 > 任务执行结果和轨迹 $\tau$.
- 初始化环境, 得到初始截图 $o_1$.
- 初始化短期历史 $H_{\mathrm{short}}$ 和长期里程碑记忆 $H_{\mathrm{long}}$.
- 对第 $i$ 步, Orchestrator 根据当前上下文生成: $$ t_i,a_i=F_O(I,R_i,o_i,T,H_{\mathrm{short}}) $$
- 如果 $a_i$ 是普通 GUI action, 调用 Grounder 定位并用 PyAutoGUI 执行.
- 如果 $a_i=\mathrm{call\_search\_agent}(q)$, 在隔离浏览器环境中搜索并返回教程 $T$.
- 如果 $a_i=\mathrm{call\_code\_agent}(g)$, 调用 Coder 通过命令行或脚本完成子任务, 再由 GUI 状态验证.
- 执行动作后得到新截图 $o_{i+1}$.
- 用步骤总结器比较动作前后截图: $$ S_i,s_i=F_S(O_{i-1},o_{i-1},o_i,\tilde{o}_{i-1}) $$ 其中 $S_i$ 是单步摘要, $s_i$ 表示这一步是否执行成功.
- RMA 基于长期记忆生成反思、里程碑标记和可复用知识: $$ R_i,m_i,k_i=F_R(O_{i-1},o_i,H_{\mathrm{long}}) $$
- 如果 $m_i=\mathrm{true}$, 把当前摘要和截图写入 $H_{\mathrm{long}}$.
- 如果 RMA 判断任务 Completed / Infeasible, 则结束; 否则继续下一步.
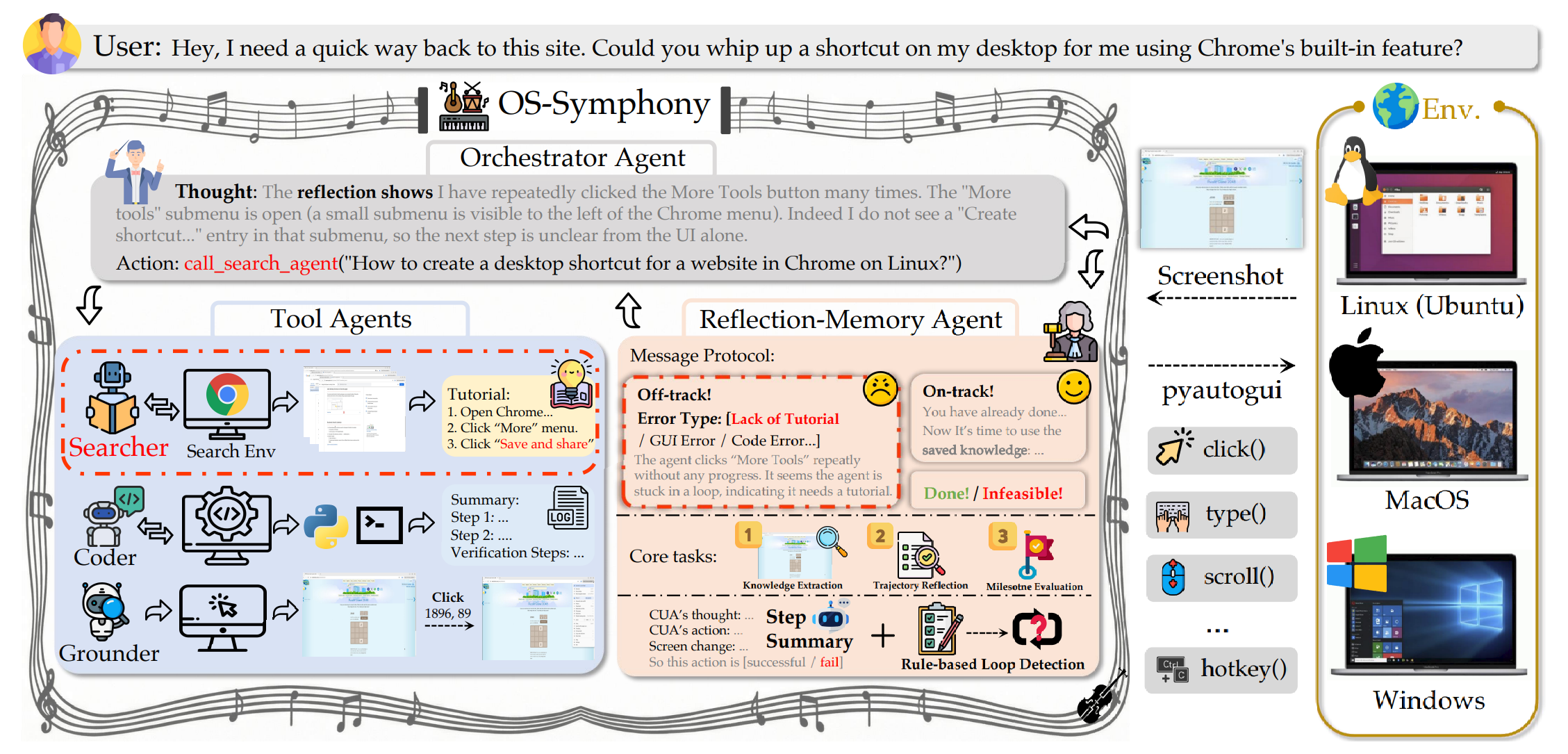
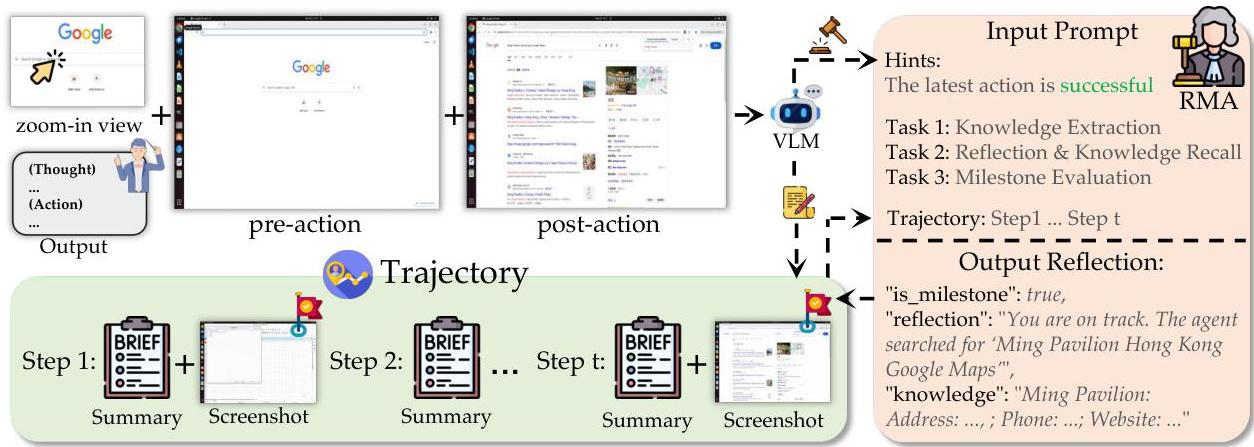
Reflection-Memory Agent
RMA 是这篇文章最关键的模块. 它的目标是选择性保留里程碑截图, 并把历史轨迹压缩成可审计的摘要.
每一步执行后, 系统先做步骤级别的总结.
$$ S_i,s_i=F_S(\mathcal{O}_{i-1},o_{i-1},o_i,\tilde{o}_{i-1}) $$$\mathcal{O}_{i-1}$ 是上一轮 Orchestrator 的输出, $o_{i-1}$ 和 $o_i$ 分别是动作前和动作后的截图, $\tilde{o}_{i-1}$ 是一个动作区域的 zoom-in crop. $S_i$ 是步骤总结, $s_i$ 是一个布尔值, 表示这一步是否执行成功.
长期记忆写成:
$$ H_{\mathrm{long}}=\{(S_j,o_j,m_j)\}_{j=1}^{i-1} $$其中 $S_j$ 是单步摘要, $o_j$ 是保留下来的截图, $m_j$ 是里程碑标记. RMA 在每一步输出:
$$ R_i,m_i,k_i=F_R(O_{i-1},o_i,H_{\mathrm{long}}) $$其中 $R_i$ 是给 Orchestrator 的反馈, $m_i$ 决定是否作为里程碑保存, $k_i$ 是从页面里抽取的潜在知识 (去向不明).
RMA 的协议把状态分成四类:
- On-track: 当前轨迹正常, 继续执行.
- Completed: 任务已经完成.
- Infeasible: 任务不可完成.
- Off-track: 轨迹偏离, 需要纠正.
Off-track 又分成四种错误:
- GUI Error: 底层 GUI 操作没有达到预期.
- Lack of Tutorial: agent 缺少流程知识.
- Code Error: Coder 执行结果和 GUI 状态不一致.
- Other Error: 目标漂移、幻觉、事实错误等其他问题.
为了检测循环, 论文还写了一个 rule-based 信号. 如果最近 $N$ 步和更早的一段轨迹在截图和动作上都高度相似, 就触发循环检测, 给 RMA 一个比较强的 Lack of Tutorial 信号.
工具 Agent
OS-Symphony 的工具 agent 包括 Searcher、Grounder 和 Coder.
-
Searcher 是论文特别强调的部分. 传统 RAG 往往只抓网页文本, 但 GUI 教程里很多信息藏在截图、按钮布局和菜单层级里. 因此论文的方法是 Orchestrator 在发现缺少流程知识时, 生成一个 “How to” 查询, 然后 Searcher 在一个隔离的浏览器 sandbox 里像人一样浏览网页.
Searcher 的动作包含点击、输入、滚动、完成和失败, 会访问多个页面交叉确认信息. 如果没有找到高相关内容, 返回 fail; 只有在确定教程和当前问题高度相关时, 才返回结构化的逐步教程 $T$.
-
Grounder 分两类, 其一是 GUI grounding 模型直接根据元素描述输出坐标. 其二是对 Word、PowerPoint 这类文本密集场景, 先 OCR 得到
{text,id,bbox}表, 再让 VLM 选 ID, 最后查坐标. -
Coder 则负责适合用代码完成的子任务, 例如文件编辑、配置修改、批处理. Orchestrator 把一个自包含子任务交给 Coder, Coder 执行后返回简短摘要, 再由 Orchestrator 通过 GUI 状态验证. 如果 Coder 失败, 再退回 GUI 操作. (这种混动是否是一种 trick?)
实验
OSWorld 和 WindowsAgentArena 上达到 SOTA. 这里强调一下消融实验:
| Setting | Daily | Workflow | Avg. |
|---|---|---|---|
| w/o Search, Refl. | 49.60 | 37.33 | 51.90 |
| w/o Search | 50.65 | 48.06 | 53.78 |
| + Unimodal Search | 56.10 | 39.30 | 54.81 |
| + Multimodal Search | 61.86 | 47.37 | 58.05 |
| w/o Reflection | 60.20 | 39.23 | 54.38 |
| + Reflection w/ STM | 56.10 | 39.49 | 54.01 |
| + Reflection w/ LTM | 61.86 | 47.37 | 58.05 |
- Multimodal Search 比纯文本搜索更适合 GUI 任务, 尤其在 Daily domain 里收益明显. 这类任务经常需要软件使用教程或外部知识, 单纯 parse 网页文本容易丢掉按钮位置和菜单层级.
- 反思模块不是“有就好”. Reflection w/ STM 只看短期历史, 效果甚至比 w/o Reflection 更差. 这说明 naive reflection 会带来额外上下文和错误反馈, 反而干扰决策. 真正有效的是带 milestone long-term memory 的 RMA.