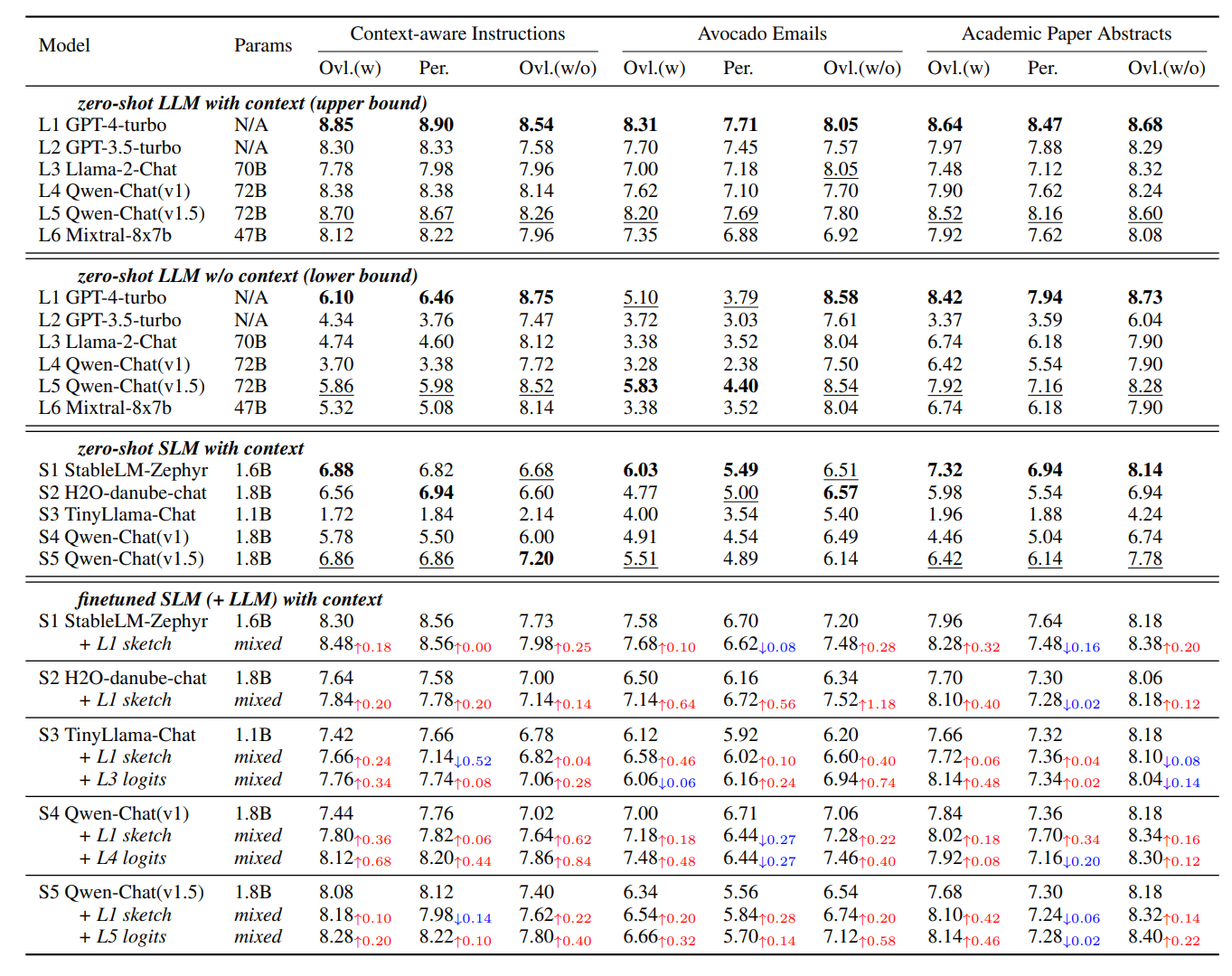
EcoAgent
论文 [] 设计了一个端云协作的闭环推理和执行算法 EcoAgent:云端大模型做规划与反思,端侧小模型做 UI 操作、结果验证和屏幕摘要.
输入是用户指令 Ins 和初始手机屏幕状态 S0,输出是最终手机状态 Sf. 算法先调用云端 Planning Agent 做初始规划:
得到一个计划 P0,每个步骤是一个二元组:$(ST_t, EX_t)$. 其中 ST_t 是第 t 步操作目标,EX_t 是该步的期望结果. 然后端侧 Execution Agent 根据当前屏幕 S_t 和步骤 ST_t 执行动作,Observation Agent 再检查执行后的屏幕 S_{t+1} 是否符合期望 EX_t. 如果失败,就把端侧压缩后的屏幕历史传回云端,由云端反思并重新规划.
Dual-ReACT
论文最核心的方法是 Dual-ReACT. 它扩展了传统 ReACT 的 “Reason + Act” 思路,把推理分成两层.
-
第一层是 Global ReACT. 云端 Planning Agent 先看用户指令和初始屏幕,生成一个全局屏幕描述,然后把任务拆成若干中间子目标.
$$ P_0 = GlReACT(Ins, S_0) $$ -
第二层是 Local ReACT. 对每个子目标,云端进一步生成具体可执行的步骤
$$ P_0 = {LoReACT(ST_1, EX_1), ..., LoReACT(ST_t, EX_t)} $$ST_t,并同时生成该步骤执行后的期望屏幕状态EX_t.
也就是说,端侧小模型不需要自己做复杂长程规划,只需要执行当前步骤,并判断“当前屏幕是否符合云端给出的期望”.
Execution Agent
Execution Agent 部署在设备端,输入当前屏幕 S_t 和当前步骤 ST_t,输出具体操作 O_t:
这里的 EA 是经过 GUI 操作能力适配的小多模态模型,例如 ShowUI 或 OS-Atlas. 它的强项不是复杂推理,而是视觉定位和具体点击/滑动/输入.
论文定义的动作空间包括两类. 第一类是输入操作:Tap(x,y) 等等;第二类是导航操作:PressBack() 和 PressHome(). 作者额外加入了 DeleteText() 的动作,用来清空输入框,解决输错后难以重新输入的问题.
Observation Agent
Observation Agent 也在设备端,但它的职责是验证. 它输入执行后的屏幕 S_{t+1} 和该步的期望结果 EX_t,输出验证结果 R_t:
如果 R_t = Success,说明当前步骤达成,继续执行下一步;如果 R_t = Fail,说明当前计划可能偏离了,需要触发云端反思与重规划. 论文强调,这样可以避免每一步都把截图传到云端让大模型检查,从而降低延迟、token 成本和隐私风险.
Pre-Understanding
为了让云端在失败时能重规划,系统仍然需要知道执行轨迹. 但论文不直接把完整截图作为 Memory,而是在 Observation Agent 里加入 Pre-Understanding 模块,把屏幕 S_{t+1} 压缩成文本表示:
作者认为,重规划通常不需要完整截图的所有细节,只需要知道屏幕状态如何变化、任务进展到哪里、失败点是什么. 论文提到,原始屏幕图像通常会消耗 1400+ token,而压缩后的文本描述只需要 50–150 token.
Memory Reflection
一旦 Observation Agent 判断某一步失败,端侧会把压缩后的屏幕文本 T_{t+1} 加入 Memory. 云端 Planning Agent 再调用 Reflection 模块,根据用户指令、上一轮计划和执行历史生成新计划:
这一步让 EcoAgent 的端云协作从开环变成了闭环.
Hybrid LLM
论文 [] (ICLR 2024) 提出一种混合推理方法,使用路由器结合端云各自的优势以节省成本并保持质量.

将小型模型的响应质量接近大型模型的响应质量的查询,称为“简单”查询。查询 x 的质量差定义为
$$H(x) := q(S(x))−q(L(x))$$即小模型响应 $S(x)$ 和大模型响应 $L(x)$ 之间的质量差.
确定性路由
最简单版本:对每个 query,从小模型和大模型各采样一个回答,然后用质量函数比较两者。如果小模型回答质量不低于大模型,就标为 easy:
$$ y_i^{det} = \mathbf{1}\{H(x_i) \leq 0\} = \mathbf{1}\{q(S(x_i)) \leq q(L(x_i))\} $$这里选取 BART 分数作为质量函数 $q$. 然后训练 router 做二分类, 最小化交叉熵损失:
$$ L(w) = - \frac{1}{N} \sum_{i=1}^N \left( y_i^{det} \log p_w(x_i) + (1-y_i^{det}) \log (1-p_w(x_i)) \right) $$概率性路由
当大模型比小模型强大得多时, $y_i^{det}$ 几乎永远都是取 $0$ 的, 所以需要做一些松弛平移, 引入新标签:
$$ y_i^{trans}(t) = \mathbf{1}\{H(x_i) \leq -t\} = \mathbf{1}\{q(S(x_i)) \leq q(L(x_i)) - t\} $$现在的问题是如何选取最佳的 $t$? 论文提出最大化标签之间的平均成对差异来选择 $t$:
$$ t^\ast = \argmax_t \frac{1}{N^2} \sum_{i, i'} \left| y_i^{trans}(t) - y_{i'}^{trans}(t) \right| $$用网格搜索解决. 随后再用这个去做二分类.
![]()
![]()
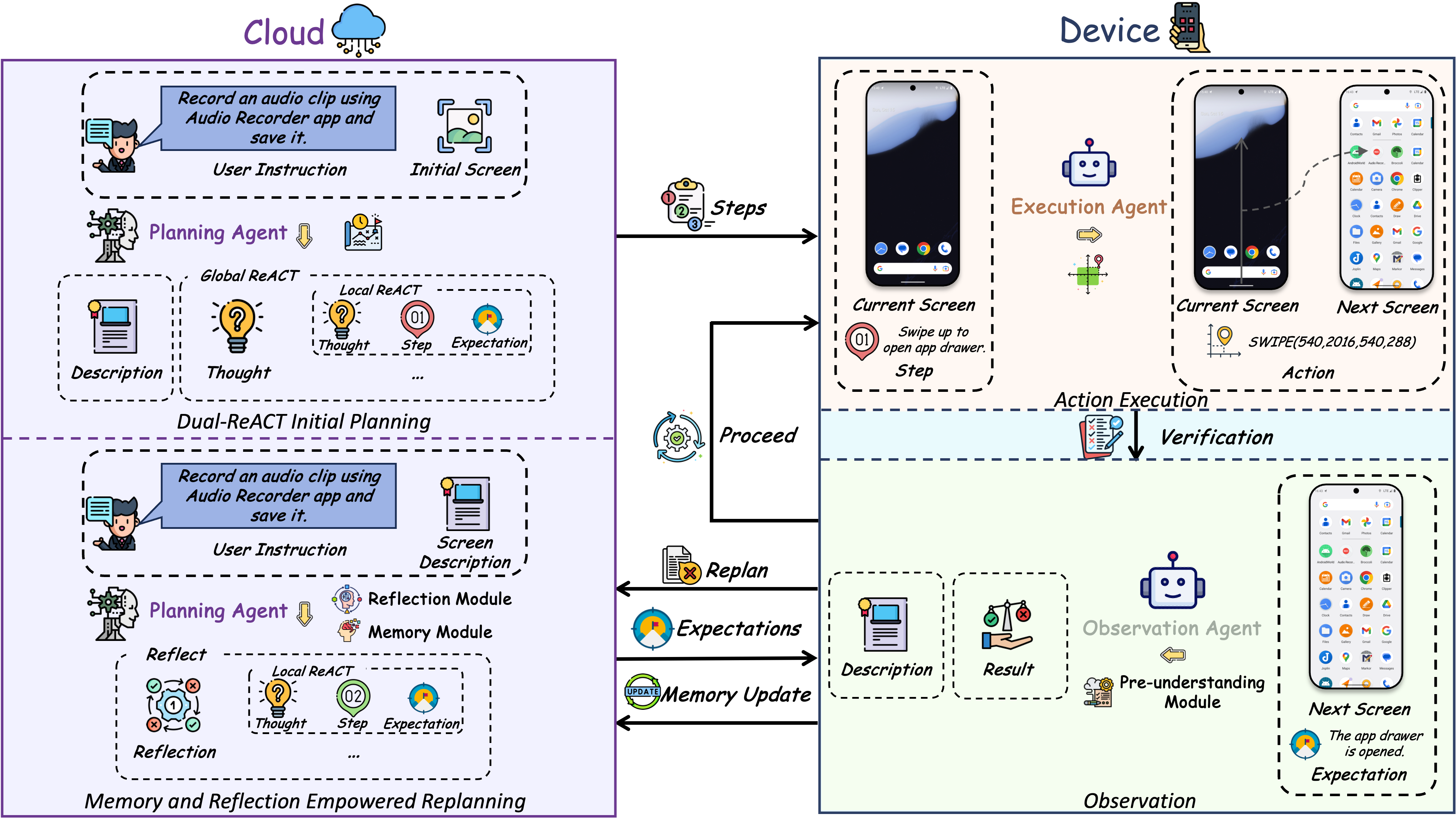
实验
下面三张图能很好说明路由的设计:



CoGenesis
论文 [] (ACL 2024) 更关心隐私上下文不能上传云端时,如何让云端大模型和本地小模型协作生成高质量个性化内容
Sketch-based CoGenesis
先让云端 LLM 在没有私人上下文的情况下,根据一般的指令生成一个草稿;然后本地 SLM 用这个草稿,加上私人上下文,生成最终内容。
显然这个想法很直接.
Logits-based CoGenesis
LLM 虽然不能看私人 context,但它每一步的 logits 或者 token 分布里包含通用语言能力、结构偏好、表达质量等隐性信息。于是每个 token 生成时,同时看 LLM 和 SLM 的输出分布,再用一个轻量 CombModel 学习如何融合。
算法Logit-Based-CoGenesis
输入 > 通用指令 $I$,私人上下文 $C$,云端大模型 $M_L$,本地小模型 $M_S$,融合模型 $\mathrm{CombModel}_\phi$,最大生成长度 $T$.
输出 > 个性化回答 $y$.
-
初始化生成序列:
$$ y_{<1} = \emptyset $$ -
对每个生成步 $t=1,\dots,T$:
-
云端 LLM 只基于通用指令和当前前缀输出分布:
$$ p_L^t = M_L(\cdot \mid I, y_{\lt t}) $$ -
本地 SLM 基于通用指令、私人上下文和当前前缀输出分布:
$$ p_S^t = M_S(\cdot \mid I, C, y_{\lt t}) $$ -
取两者的 logits / top-token 信息,输入轻量融合模型:
$$ \alpha_t = \mathrm{CombModel}_\phi(p_L^t,p_S^t) $$ -
融合得到最终 token 分布:
$$ p^t = \alpha_t p_L^t + (1-\alpha_t)p_S^t $$ -
从融合分布中选择下一个 token:
$$ y_t \sim p^t $$ -
重复直到生成结束符或达到最大长度。
-
返回:
$$ y = (y_1,\dots,y_T) $$
论文实现里,CombModel 是一个三层神经网络;每一步只使用 LLM 和 SLM 的 top-10 logits,训练时 LLM 和 SLM 共享同一个目标回答,并用验证集 early stopping。

实验